How do we know what we see ? |
||||||||||
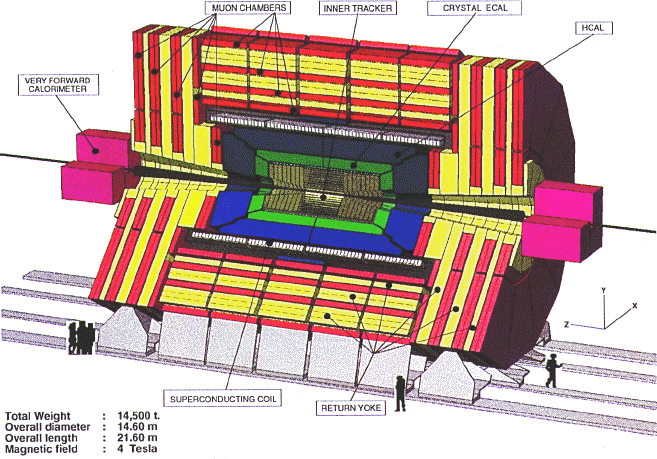
IntroductionParticle accelerators create collisions among high-energy particles in order to produce new particles. A large variety of particles may be produced in each collision, but only a few are of special interest. How do we recognize these? In the following, I'll explain the basics of particle detection and event selection. Detecting particlesTypical modern multipurpose detectors surround the interaction point - where the accelerated beams collide - in successive layers of subdetectors.
| ||||||||||
|
|
||||||||||
| Fig 2. Simulated charged particle "tracks" as seen in the ATLAS detector. |
|
|
| Fig 3. Simulated electromagnetic shower in the liquid Argon calorimeter of the Atlas detector at LHC. |
Hadrons are more penetrating and can pass through the
electromagnetic calorimeters with little loss of energy, since they don't
interact so easily with electrons, they prefer the atomic nuclei. hadronic
calorimeters therefore typically consist of some heavy material,
like lead or steel. A hadron hitting the nucleus of an atom produces secondary
particles, which in turn hit other nuclei, producing more particles, until all
the incoming energy is spent. This shower is usually sampled by layers of
scintillator or gas detectors that produce a small pulse proportional to the
number of particles passing through.
There is only one type of charged particles that can pass through all the
material in the calorimeters, muons. They are very much like electrons, only
heavier and much more penetrating. Their tracks are measured again in the
muon chambers located outside the hadronic calorimeters, adding more
points at a large distance, thereby improving the precision of the
measurement. Because so few particles reach the muon chambers, the ones that
do can be easily identified as muons, providing a very strong
identification. When you look at a typical detector, what you see is actually
the outside of the muon chambers. The only long-lived particles not seen in
the detector are the neutrinos, neutral, weakly interacting
particles. Their interactions are in fact so weak, that they easily pass
through the Earth without notice, and they can only be detected by
specialized detectors. But we still can recognize their presence indirectly,
by exploiting the conservation of energy and momentum. Since the incoming
beams are symmetric, the momentum of any particles going one way must be
balanced by other particles going the other way. So if we find an imbalance,
we know that the missing momentum was carried away by neutrinos.
Fig. 4. The hadronic calorimeter of CMS, a contribution from Fermilab.
Fig 5. Reconstructed event with an electron (red), two jets of particles (blue) and a
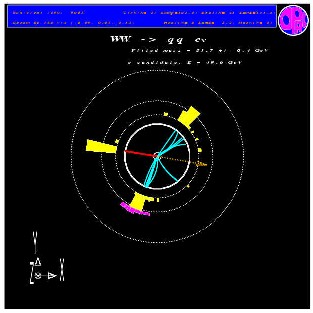
neutrino (dashed) seen by the OPAL detector at LEP.
With the advance of technology particle accelerators get more and more powerful, and detectors get bigger and bigger with ever increasing resolution. This naturally leads to a rise in the amount of raw data produced, so the latest technology must also be used to read out and interpret this data, leading to new solutions being introduced at the last minute and upgrades of working systems to improve performance or delay costs. Below I describe a typical solution with a few numbers to give you a feeling of the scale of the problem, but remember that this is just an example. Particles in the accelerator collide thousands or millions of times each second, but most of the collisions are uninteresting. (Remember, we want to discover something new!) How to select the few events that we deem important? This is started by the trigger subsystem. For efficiency, it is always divided in two or more levels. At the first level trigger, in a simplified view, imagine that each time a subdetector sees something that might be part of an interesting event, it raises a flag. The central trigger processor looks at these flags, and when it sees a predefined pattern, like 'two high-momentum muons and two high-momentum electrons', it knows the event might be interesting and instructs all the subdetectors to send their data on, otherwise after a timeout each subdetector throws away the data. With millions of collisions each second, the first level trigger can only keep in the order of one in a hundred.
|
|
| Fig 6. The high-level trigger farm of the CDF detector at the Tevatron (under construction). |
While each subdetector sees only a small fragment of each event, we
need to look at each event as a whole. It is the task of the event
builder to combine the fragments into entire events. Since no
single computer could cope with the data rate of the entire detector,
we use many computers, each dealing with a small fraction of the events,
but collecting data from all the parts of the detector. Think of this as a big
network switch: the fragments of an event come from all over the detector and are sent to
the one computer collecting this particular event, the next event is sent to the
next available computer and so on.
The assembled data from the event builder is passed on to the
filter farm, where computers look at the event as a whole and
apply the high-level trigger selection criteria to decide
whether this event is worth storing. These criteria are established
based on computer simulations of the 'interesting' processes and 'uninteresting' background events that might look very similar.
At this stage a mini-analysis of the event may be performed to identify the
physics process observed, but there is not much time because of the many incoming events
waiting. Selected
events are written to permanent storage for detailed analysis.
Raw data is obtained from the detector and then stored on tape at
the level of individual channels, that is the position of all the hits
in the tracker or the measured energy in each individual calorimeter
crystal. There is no connection among the many hits and
deposits caused by the same particle.
To make sense of it, one needs to get back the original particles
that made these hits and then find out what the original parameters of
those particles was. This process is called the reconstruction, and it involves many iterations of pattern
matching and function fitting, to get a list of particles that were
observed in the detector.
The reconstruction uses calibration constants and other
parameters of the detector to get the best estimate of the original
particles. However, these parameters can be later improved, often
using the data itself to better understand the secondary effects in
the detector. As the data are reprocessed with the improved
parameters, their quality improves, they 'mature'.
Once the data has been fully processed, detected particles have been
reconstructed, and the 'real' data analysis can start. Physicists, including
graduate students, try to answer specific questions, like Is there a Higgs
particle with a mass of x GeV? or What are the properties of the top
quark? The general method is to use computer simulation to find out
what would be the effect of a given assumption on our data, then try to isolate
that effect by selecting events that are similar to the signal we are looking
for. The remaining fraction of background events can be estimated from the
simulation of all other processes that might fake the signal, and these must be
taken into account when estimating the error of the measurement. Once we have
selected a sample of events that mostly contain the particle we are looking for,
we can study its properties, or if we can not select such a sample, we can
derive a negative result that excludes the given particle with a given
probability. For example you might generate simulated samples of Higgs bosons
assuming various masses, compare these signal samples to all the background
samples that only contain the standard processes, and define a set of
requirements or cuts that you can apply to the data to select Higgs-like
events. From theoretical calculations you know how many Higgs particles you
expect to be produced and from the signal simulation you know how many of these
you would see in your selected sample. From the background simulation you know
how many events you would find that look like Higgs but are not. Comparing these
numbers you calculate a probability, and you either say that there is a 99.9%
chance that the experiment saw Higgs particles, in this case you can calculate
their mass and estimate the error of the measurement, or you say that there is
95% chance that no Higgs particles were produced, therefore the Higgs particles
must be heavier than a given mass.
For a gentle introduction to particle physics in general, including
detectors, try http://particleadventure.org/particleadventure/index.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}